Интеллектуальный анализ данных >> О кафедре >> Красивая математика для вашего удобства
Знаете игру «испорченный телефон»? Где по цепочке на ухо передают слово, а потом смеются, услышав, во что оно превратилось в конце. Вот примерно это и случается иногда с информацией, пока она путешествует от отправителя к получателю.
Сама по себе точная передача данных – старая задача. Когда-то ее решали путем надежной упаковки, например, делая невскрываемые конверты из глины – как шумеры четыре тысячи лет назад. Теперь, в эпоху «цифры», диапазон проблем сильно расширился – добавились такие направления, как интернет вещей (IoT), защита информации, хранение больших массивов данных.
Тут-то и вступает в дело красивая математика. Клод Шеннон, основатель теории информации, опубликовал свою знаменитую статью «Математическая теория связи» («A Mathematical Theory of Communication») еще в 1948 году, и тем снабдил уже несколько поколений теоретиков и практиков передачи данных пока недостижимым идеалом: он доказал теоретическую возможность создания помехоустойчивых кодов, обеспечивающих максимально достижимое качество связи – но не объяснил, как именно такие коды могут быть построены.
С тех пор было создано уже несколько поколений кодов, и каждое использует своих предшественников, приспосабливаясь к переменам в средах передачи и хранения данных – объему, скорости, способам упаковки информации. Коды Рида-Соломона, турбо-коды, полярные, сверточные, с малой плотностью проверок – это все названия инструментов обнаружения и коррекции ошибок.
Из семи наиболее распространенных методов помехоустойчивого кодирования четыре разработаны или впервые исследованы в ИППИ РАН: обобщенные каскадные коды (GC codes), коды с малой плотностью проверок (LDPC codes), алгебро-геометрические коды (AG codes) и сверточные МПП-коды (Spatially-Coupled LDPC codes).
Пытаетесь прочесть старый потрепанный CD – вам помогают прочитать его коды Рида-Соломона, один из самых старых методов. Или алгебро-геометрические коды – это красивая математика, чего самого по себе достаточно, чтобы их полюбить – но еще это тот случай, когда матанализ, мучение для многих старшеклассников, оказывается практически полезен.
По словам Алексея Фролова, кандидата физ.-мат. наук, старшего научного сотрудника Сколковского института науки и технологий и Лаборатории №3 ИППИ РАН, а также руководителя проекта по заказу компании Huawei «Разработка оптимальных процедур исправления ошибок для физического уровня будущих сетей 5G», наблюдается две общих тенденции. Во-первых, использование максимально простых алгоритмов кодирования и декодирования. Они позволяют, например, увеличить срок работы мобильного устройства от батареи и снизить тепловыделение – для обработки простого кода требуется меньше мощности процессора, поэтому можно уменьшить площадь кристалла.
Во-вторых, необходимость учитывать громадный рост количества передаваемой в единицу времени информации. Миллионы пользователей по всему миру смотрят в своих телефонах бесчисленные видеофайлы, ищут что-то в поисковых системах, разговаривают друг с другом через интернет – и все это требует невиданных скоростей обработки получаемых данных. И вот уже турбо-коды, для которых 200 Кбит/сек – максимум для изначального 3G – и даже 10 Мбит/сек (HSPA+) были легким орешком, потому что на таких скоростях аппаратура успевает отправить запрос и получить еще раз «потерявшийся» или «испорченный» пакет, так, что пользователь не заметит задержки, для грядущего 5G не подходит совершенно. А это мы еще не упомянули трудности, связанные с обработкой большого числа потоков данных – но упомянем их ниже.
Скорости 5G измеряются уже в гигабитах в секунду – пробные запуски технологии в России в 2016 году дали, например, 4,5–4,9 Гбит/сек, а в апреле 2017 китайская компания Huawei – партнер ИППИ в области разработок средств коррекции ошибок – объявила о совместном с Telenor тестировании технологии 5G с результатом до 70 Гбит/сек.
«Трафик стал больше, пользователей становится больше и соответственно нужно повышать скорость передачи, при этом алгоритмы кодирования и декодирования должны быть достаточно простыми, хорошо распараллеливаться и, соответственно, работать быстро, – объяснил Алексей Фролов. – У турбо-кодов с этим проблема, потому что они были разработаны с учетом невысоких скоростей передачи данных, и декодеры постепенно перестают справляться с нынешними требованиями. И все, кто занимается кодами, ставят эксперименты, придумывают идеи, хотят разработать метод, чтобы проблемы со скоростью решить».
Повышение скорости создает для разработчиков новые проблемы – на линиях оптоволоконной связи тоже встречаются ошибки, но гораздо реже, чем в беспроводной. «У оптической связи скорости выше, последнее, что я слышал, было 1 терабит в секунду. В беспроводной получается, что если мы поняли, что декодер не отработал, то можем повторить [отправку данных], потому что требуемая скорость передачи небольшая, а в оптике скорость огромная, там уже информацию не повторяют. Поэтому к кодам работающим в оптических каналах связи предъявляется очень жесткие требования к выходной вероятность ошибки на бит – порядка 10 (т.е. допускается, чтобы из 10 выходных бит только один был ошибочным). Проверить выполнение этого требования методами классического моделирования очень сложно, так как для этого нужно очень много времени. Для ускорения процесса можно использовать графические ускорители и программируемые логические интегральные схемы (ПЛИС), что существенно увеличивает сложность разработки программ моделирования. Вот почему для данной задачи очень важно уметь оценивать выходную вероятность ошибки теоретически. В этом случае удается избежать трудоемкого имитационного моделирования», – рассказал Алексей Фролов.
Но использование кодов обнаружения и коррекции ошибок не ограничивается передачей пользовательских данных. Еще одна часть наступающего будущего – интернет вещей. Он отличается от «интернета для человека» – в нем идет постоянный поток небольших пакетов от сотен и тысяч устройств. Эту информацию базовая станция должна не только получить и соответственно отреагировать, но еще и учитывать приоритеты – очевидно, сообщение пожарной сигнализации или системы обслуживания лифтов в многоэтажном здании важнее, чем вопль холодильника о недостатке сыра.
Специфика работы с такими данными – очень короткие пакеты и большое число «пользователей» на небольшом диапазоне частот. Если большие пакеты позволяют использовать существующую теоретическую базу построения кодов и более-менее уверенно восстанавливать потерянную часть информации, то с короткими так не получается. Между тем, информация может быть жизненно важной, и ее еще нужно увязывать с сообщениями других датчиков.
Но прежде чем обрабатывать эти пакеты, нужно их сперва получить, да не когда-нибудь, а поскорее. Как распределить принимающие мощности базовой станции, чтобы вовремя принять все эти сотни и тысячи сообщений? Есть три основных способа разделения пользователей – временное, частотное и кодовое.
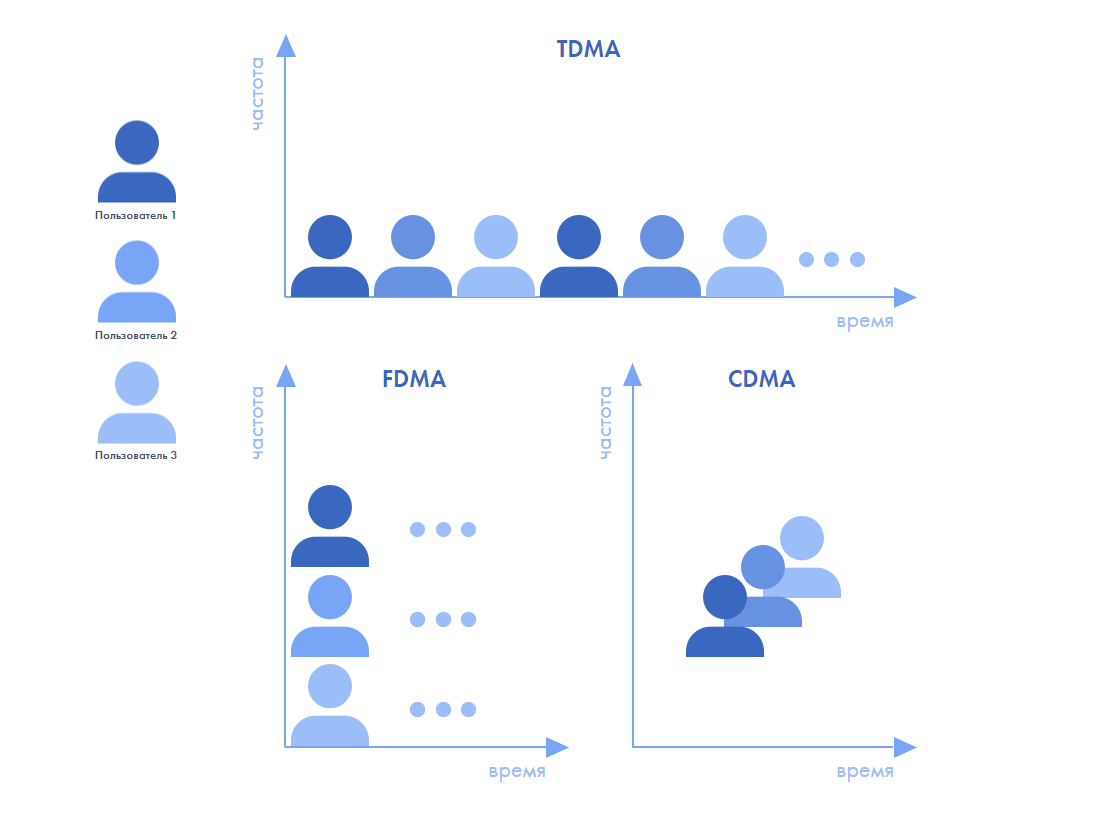
Это нетривиальная задача, когда речь идет не о видеофильме. Во всех трех вариантах для каждого устройства выделяется слот, если пользователей, обменивающихся информацией через базовую станцию, больше чем у нее есть входных каналов. При временном разделении каждое устройство получает кусочек времени – но из-за этого возникает задержка. При частотном – получает кусочек частоты, но диапазон ограничен.
Наконец, при кодовом каждому устройству приписывается определенная последовательность, сигнатура, по которой станция определяет, откуда этот конкретный пакет данных пришел. И тут есть своя сложность – нужно выбрать длину последовательности. Если она будет слишком короткой, это ограничит число пользователей. Если слишком длинной – пользователей можно будет подключить больше, зато будет нарастать задержка. Таким образом, все три вышеупомянутых метода (все они – вариации метода ортогонального множественного доступа) приводят к значительному увеличению задержки передачи пакета. Поэтому сейчас активно исследуются (например, в комитете стандартизации 3GPP) методы неортогонального множественного доступа. Новая идея заключается в том, чтобы некоторые слоты можно было предоставлять пользователям для совместного использования – это позволит уменьшить задержку передачи пакета.
Мы уже упоминали несчастные CD, потрепанные временем. А как насчет локального массива данных, измеряемых сотнями терабайтов, например, библиотеки генетических данных? Ведь чем больше физических носителей, тем чаще какой-нибудь из них выходит из строя.
Можно просто хранить несколько копий, и это позволит очень быстро информацию восстановить. Предположим, содержимое каждого диска мы храним в трех экземплярах – если один выходит из строя, мы тут же задействуем другой. Но это очень неэкономно – у нас фактически 200% служебной информации, да еще большие расходы на собственно дополнительные носители, помещения для них, обслуживание, энергоснабжение, отведение тепла и прочее.
А вот если мы используем RAID 6, основанный на тех же кодах Рида-Соломона, – там каждый блок состоит из шести дисков, из которых четыре содержат полезную информацию, – то получаем уменьшение объема информации служебной до 50%, в четыре раза. Но тут другая сложность – восстановление резко замедляется, потому что алгоритм предполагает, что чтобы восстановить содержимое одного диска, нужно считать информацию с четырех, а не с одного.
То есть повышение надежности достигается ценой снижения скорости восстановления. Это не очень хорошо, нужно сделать следующий шаг. Очевидно, чаще всего из строя выходит один диск (бывает, что два одновременно, но гораздо реже). Требуется, чтобы этот один восстанавливался быстро, брал информацию с других дисков, загружая при этом служебную информацию – именно эту задачу решил Александр Барг, старший научный сотрудник ИППИ, профессор Университета Мэриленда, одного из партнеров ИППИ.
Профессор Барг (совместно с И. Тамо из Университета Тель-Авива) предложил оптимальные коды с локальным восстановлением (Locally Recoverable Codes) – сейчас это одна из наиболее интенсивно развивающихся областей теории кодирования в контексте задач распределенного и облачного хранения данных. Для этих кодов определено понятие «восстанавливающего множества» – это минимальное множество символов (как единиц информации), которое требуется для того, чтобы безошибочно восстановить утерянную информацию.
При использовании свойства локального восстановления важно аккуратно сбалансировать нагрузку. Предположим, один диск вышел из строя. В этом случае запросы пользователей перенаправляются на работающие, и может получиться так, что нагрузка на работающие диски распределится непропорционально – в результате повысится вероятность следующего сбоя, а в пределе можно получить каскадный сбой, и это очень, очень плохо.
Поэтому естественным обобщением кодов с локальным восстановлением стали коды с несколькими непересекающимися восстанавливающими множествами. Иными словами, восстанавливающая информация распределена по разным дискам, так что если несколько пользователей захотят одновременно получить информацию с отказавшего узла, то у каждого пользователя будет отдельное, непересекающееся с другими восстанавливающее множество – то есть их запросы будут обработаны параллельно с использованием разных дисков, что сэкономит время и позволит избежать концентрации нагрузки на одном из еще работающих дисков.
Можно устремиться в будущее еще дальше, к квантовым вычислениям, или обратиться к «стратегическим» вопросам вроде защиты информации. Например, можно разработать код, запирающий секретную информацию так, что доступ к ней возможен по принципу банковской ячейки. Как известно, чтобы открыть ее, нужно, чтобы пришли обладатели двух ключей, а в одиночку это невозможно. Так же работает и такой виртуальный замок – чтобы получить информацию, нужно, чтобы «собрались» вместе не менее определенного числа пользователей.
Но, пожалуй, можно и остановиться. Только хотелось бы отметить одно очень приятное свойство работы над разнообразными кодами – человек, имеющий вкус к математике, получает двойное удовольствие. Потому что ему предлагаются интереснейшие и очень красивые теоретические задачи, и, одновременно, возможность увидеть, как работа принимает практическое воплощение в существующих устройствах. Что может быть лучше для живого ума!
Нодар Лахути, ТАСС-Чердак
| 







