Интеллектуальный анализ данных >> О кафедре >> Оцифрованные нервы
Оцифрованные нервы
Лаборатория анализа данных в нейронауках
Рентгеновские снимки, данные ЭКГ, разнообразные анализы, истории болезни с назначениями лекарств – современная медицина построена на данных. Сейчас их больше анализируют люди, чем компьютеры, но все постепенно меняется. Юлия Додонова, один из сотрудников сектора анализа данных в нейронауках ИППИ РАН, рассказала, как компьютерные алгоритмы помогают в лечении и изучении различных психиатрических и нейродегенеративных заболеваний.
— Чем занимается ваш сектор анализа данных в нейронауках?
— Сейчас у нас три основных направления. Первое связано с анализом клинических данных по болезни Гентингтона. У нее достаточно широкая симптоматика: у пациента появляются моторные нарушения – непроизвольные, пританцовывающие движения, к которым часто добавляются еще психические расстройства. Болезнь Гентингтона в каком-то смысле модельная для нейронаук, потому что мы точно знаем, от чего она возникает. Если в одном специфическом гене, кодирующем белок гентингтин, у человека будет больше 36 повторов CAG-триплета, то у него точно разовьется болезнь Гентингтона – вопрос только, когда именно и с каких симптомов начнется заболевание. Например, если обнаружено около 45 CAG-повторов, то в среднем у таких пациентов болезнь проявится в возрасте около 40 лет, однако разброс очень велик: для кого-то дебют может произойти в 20 лет, а для кого-то – в 60. Мы как раз учимся предсказывать на основе семейной истории и данных пациента дебют точнее.
— Но болезнь Гентингтона все равно остается неизлечимой.
— Сейчас да, но можно облегчать ее симптомы. Например, из-за психиатрической составляющей пациенты с болезнью Гентингтона могут быть склонны к суицидальному поведению. Как минимум раз в год они проходят беседу, во время которой врач обращает внимание на «красные флаги» – значимые, угрожающие события, например признаки повышенной опасности суицида. Если вовремя обнаружить такие особенности поведения, то можно действовать превентивно, в том числе обратить внимание ухаживающих родственников. Однако врач далеко не всегда замечает эти «красные флаги», и предсказательные модели, которые мы строим, должны помочь ему быть точнее в прогнозах. Другая задача, связанная с болезнью Гентингтона, – это сравнение лекарственных препаратов: можно взять истории лечения разных пациентов и посмотреть, какой эффект оказывало то или иное лекарство.
— Откуда вы берете клинические данные для анализа?
— Есть большой международный проект Enroll-HD с базой примерно на 6 тысяч пациентов, среди которых есть как манифестировавшие, так и люди с еще не проявившейся мутацией, а также большая контрольная группа здоровых людей. Мы сотрудничаем с ведущим исследователем этого проекта Бернхардом Ландвермайером (Bernhard Landwehrmeyer), а также с российским участником проекта – научным центром неврологии и, в частности, Юрием Селиверстовым. Вообще, задача с Гентигтоном – это такой классический случай анализа и, как сейчас говорят, майнинга данных: у вас в базе есть условный «Иванов», и для него имеется длинная-длинная строка разных клинических данных: результаты когнитивных тестов, результаты моторных тестов, какие лекарства и какими дозами он принимал, беседы с родственниками. И так – для большого количества пациентов.

Картина Питера Брейгеля Младшего «Пляска Святого Витта в Моленбеке». По мнению некоторых исследователей, на этой картине изображены люди, страдающие болезнью Гентингтона.
— Какое второе направление вашей работы?
— Вторая история – это современные алгоритмы глубокого обучения на медицинских изображениях, для нас это снимки мозга человека разной модальности. Например, мы работаем со снимками мозга здоровых людей, пациентов с болезнью Альцгеймера и промежуточной стадией – умеренными когнитивными нарушениями. Болезнь Гентигтона – очень редкое заболевание, меньше одного случая на сто тысяч человек, а болезнь Альцгеймера появляется гораздо чаще. Если сложить все экономические затраты на лечение и потерянные по нетрудоспособности человеко-часы, тогда по оценкам Всемирной ассоциации по болезни Альцгеймера, эта сумма станет восемнадцатой экономикой мира. Соответственно, есть критичная даже в глобальных масштабах задача – предсказать развитие болезни и как можно раньше начать превентивное лечение. Сейчас появляются новые методы диагностики, например с использованием позитронно-эмиссионной томографии, но в России такой дорогой технологии пока нет. Возможна еще процедура с забором спинномозговой жидкости, но у нее тоже есть минусы: она слишком болезненная и тяжелая для людей в возрасте. Поэтому мы учимся предсказывать развитие Альцгеймера на основе различных изображений мозга: вот приходит к врачу МРТ-изображение (изображение, полученное с помощью магнитно-резонансной томографии – прим. «Чердака»), и хорошо бы, чтобы у него был алгоритм для автоматического распознавания стадии заболевания, а в идеале – оценивания вероятности ухудшения состояния. Это в чистом виде задача для алгоритмов глубокого машинного обучения.
— Получается, все сводится к задачам распознавания изображений?
— Да, но с некоторыми нюансами. К примеру, у нас недавно приняли работу, в которой студенты не только решали определенную задачу классификации стадий заболевания, но и визуализировали, куда именно смотрит нейронная сеточка на картинке, когда отличает болезнь Альцгеймера от нормального стареющего мозга. Это такая особенность медицинских задач: здесь пользователю важно понимать, почему алгоритм принимает то или иное решение. Есть очень много побочных вещей, связанных с предварительной обработкой медицинских изображений: в идеальном случае вы хотите работать только с изображениями мозга или, например, только серого вещества, а в реальности у вас есть только картинка всей головы целиком, и нужно еще отсегментировать интересные вам фрагменты. Есть и чисто структурные особенности изображений в медицинских задачах: в классическом распознавании образов работают с двумерными картинками, а у нас МРТ-изображения даже в самом простом случае – трехмерные массивы данных, а есть еще другие модальности, такие как функциональная МРТ (фМРТ) и диффузионно-тензорная МРТ (дМРТ).
— Какую информацию можно вытащить из этих изображений?
— На обычном структурном снимке МРТ мы можем видеть только серые области, так называемое серое вещество, про которое мы знаем, что это тела нейронов, и более светлые области – зоны, в которых проходят отростки нейронов, аксоны. И даже в самом хорошем МРТ снимке очень низкое пространственное разрешение: в одном вокселе (аналог пикселя в трехмерном пространстве – прим. «Чердака») могут быть десятки тысяч нейронов и, при этом, никакой информации о структуре их связей. С помощью дМРТ как раз пытаются «восстановить» направления крупных пучков нервных волокон – естественно, в силу низкого пространственного разрешения это тоже можно делать только косвенным образом, оценивая в каждом кубике изображения диффузию молекул воды в разных направлениях. Если в конкретном кубике белого вещества диффузия в определенном направлении ограничена – вероятно, там проходит тракт миелинизированных волокон. Соответственно, этот метод дает дополнительную информацию, которой обычный МРТ снимок не несет. Есть еще третья модальность: фМРТ, в которой по притоку обогащенной кислородом крови можно косвенно измерять активности той или иной зоны мозга.

Американский художник Уильям Утермолен за свою жизнь нарисовал множество автопортретов. В 1997 году он узнал о том, что болен Альцгеймером, и с тех пор характер его автопортретов стал меняться.
— Вы говорили еще про третье направление.
— Третья история у нас – про анализ мозга человека как единой сети, так называемого коннектома. Термин «коннектом» придумали в 2005 году по аналогии с геномом: геном – это совокупность всех генов в организме, а коннектом – совокупность всех связей между нейронами. У Себастьяна Сеунга (Sebastian Seung), активного исследователя в области коннектомики, есть прекрасная лекция на TED, где он несколько провокативно утверждает, что именно наш коннектом кодирует всю нашу личность. Но сейчас коннектом расшифрован только для очень маленького организма – червя C. elegans, у которого всего около 300 нейронов, для человека это пока невозможно. Просто для понимания масштабов бедствия: у Сеунга есть проект EyeWire – веб-игра, в которой волонтеры помогают ученым по трехмерным срезам с микроскопа восстанавливать структуру связей между нейронами. Делают они это уже пять лет, занимаются только нейронами сетчатки глаза, и проект еще далеко не закончен. Так что получить полный коннектом человека в ближайшее время совершенно нереально.
— Но если нет коннектома, то как можно его анализировать?
— Можно картировать не отдельные нейроны, а какие-то достаточно крупные зоны мозга и дальше анализировать эти зоны и макроуровневые связи между ними как некую сеть. То есть построить граф, в котором вершины будут зонами мозга, а связи между ними – трактами нервных волокон, выделенных на основе дМРТ; или подключить фМРТ и смотреть, как активируется мозг – тогда ребрами графа станут уже корреляции временных рядов, описывающих активность различных зон. Похожими данными сейчас много занимаются в теории сложных сетей, network science. Сетевые структуры используются, например, при построении рекомендательных систем, при анализе сообществ в социальных сетях или для описания семантических связей между словами в лингвистике. Правда, в коннектомике немного другая постановка задачи: например, для социальной сети у вас есть один большой граф, в котором вершины-пользователи связаны, если они добавлены друг у друга в друзья, и вы хотите предложить человеку добавить нового друга, то есть создать новую связь внутри этого же графа. А у нас есть сразу большой набор графов, каждый из которых представляет мозг одного человека, и мы хотим их классифицировать, то есть для каждого графа предсказывать метку: 0 – мозг здорового человека, а 1 – например, мозг человека с шизофренией и так далее.
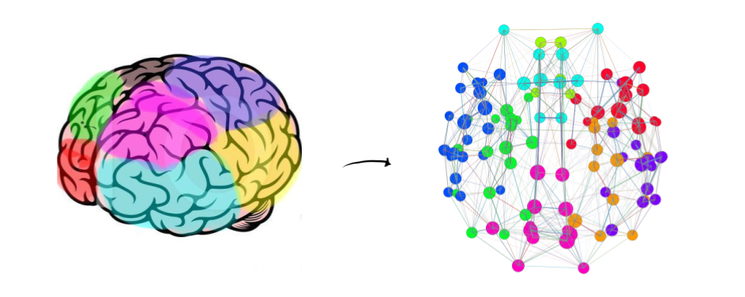
Коннектомика представляет мозг человека в виде сети, в которой отдельные регионы связаны и взаимодействуют. Рисунок: ИППИ РАН
— Нейронные сети, пишут музыку и обыгрывают чемпионов мира в го. Алгоритмы, способны понять наши вкусы по нескольким постам в фейсбуке. Среди всех этих удивительных новостей об успеха data science очень редко появляется что-нибудь про медицину. Почему?
— Одна из главных причин – это наличие данных. Алгоритмы глубокого обучения, о которых вы говорите, стали активно развиваться, когда появились большие базы данных, на которых можно обучать модели. К примеру, алгоритмы распознавания изображений сегодня можно обучать на базе ImageNet, в которой около 14 миллионов размеченных картинок. В медицине таких объемов нет – собирать данные дорого и сложно. Чтобы понимать, что в медицине – даже не конкретно в нейронауках – считается большим набором данных: в ноябре 2016 года исследовательская группа Google опубликовала результаты огромного проекта по распознаванию диабетической ретинопатии с помощью глубокого обучения на основе изображений глаза, и в этом проекте модель учится на 130 000 аннотированных снимков. И это действительно очень большой датасет, а вообще типичные масштабы медицинских данных – это сотни, максимум тысячи изображений.
— Как выходить из этой ситуации с дефицитом данных?
— Есть несколько подходов. Первый – это разнообразные коллаборации, которые объединяют усилия многих медицинских центров при аккумулировании данных. Например, есть проект ENIGMA, в котором более 500 исследователей из 35 стран собирают базу результатов нейровизуализации, а также другие типы данных для 12 психиатрических и нейродегенеративных заболеваний. Одних структурных снимков МРТ в этом проекте сейчас около 80000. Пока такого рода исследования неравномерно покрывают разные заболевания мозга и различаются по тому, какие именно данные собраны, но таких инициатив становится все больше. С другой стороны, маленькие объемы данных заставляют думать в сторону алгоритмов так называемой аугментации данных. Это искусственное, синтетическое увеличение выборки, на которой будет обучаться модель, за счет разных манипуляций – в случае с картинками это могут быть повороты, отражения, внесение шумов. Понятно, что с медицинскими изображениями такие трюки нужно применять очень аккуратно, но в этом направлении тоже возможны интересные решения.
— Как близко все это к клиническим применениям?
— Про это я уже немного говорила. Для клиники важно не просто сделать хороший алгоритм, хорошо бы еще понимать, на какие именно признаки он опирается в своей работе. Это накладывает некоторые ограничения – важна интерпретируемость моделей. Тем более, что в медицине, речь чаще идет не о полностью автоматизированном принятии решений, а о разработке алгоритмов для поддержки решений живого врача. Для каких-то задач это сделать несколько проще – например, уже сегодня есть достаточно точные алгоритмы выделения новообразований на основе изображений, но с диагностикой и прогнозированием течения нейродегенеративных и, особенно, психиатрических заболеваний все гораздо сложнее. Там до внедрения в клинику пока далеко. В этом смысле тем, кто идет в нашу область, нужно хорошо понимать, что идеальных условий для глубокого обучения на больших данных у нас, по-видимому, в ближайшее время не будет. Но это не мешает уже сейчас разрабатывать алгоритмы для собираемых данных.
МРТ мозга как картина. Изображение: Valerie van Mulukom / CC BY-SA 4.0
— Что еще нужно от студентов кроме моральной готовности к отложенным результатам?
— Мотивация, желание работать, все как обычно. И главное, да – понимание, что предсказательное моделирование на медицинских данных имеет свою специфику, о которой мы говорили выше. Мы можем научить машинному обучению, работе с глубокими нейронными сеточками, но наши задачи – это не различение кошечек и собачек и не аннотирование видео, например.
— Большие данные, нейронные сети, графы. Наверняка нужна еще серьезная математическая подготовка?
— Во-первых, мы сейчас все больше разбиваемся по направлениям и возникает такая естественная специализация: одни занимаются глубоким обучением на медицинских изображениях, другие сложными сетями. Во-вторых, мы готовы к тому, что к нам попадают студенты с совершенно разным бэкграундом: кто-то уже хорошо программирует и, например, сам пробовал решать какие-то задачи с помощью нейронных сетей, а кто-то начинает изучать Python почти с нуля, но имеет, к примеру, сильную математическую подготовку. Это не проблема. Сейчас к нам приходят ребята из двух основных мест – бакалавриата МФТИ и магистратуры факультета компьютерных наук Высшей школы экономики, в этом году появились еще студенты магистратуры Сколтеха. Физтехи обычно уже очень много умеют с точки зрения математики и алгоритмов, а студенты из Вышки гораздо разнородней по своим навыкам. Там есть ребята с совершенно разными историями: с матфака ВШЭ, с мехмата МГУ, из других университетов. Я сама закончила психфак МГУ, защитила кандидатскую диссертацию и какое-то время работала в академической психологии, но потом через магистерскую программу ВШЭ попала в ИППИ РАН.
— Психологическое прошлое помогает вам в работе?
— Помогает, да, но в каких-то самых общих вещах. Например, я по опыту психологических обзорных исследований понимаю, как могут быть устроены большие наборы тех же клинических данных и какие проблемы там могут возникать. Еще в чем-то, может быть, мне немного легче общаться со специалистами из предметной области, понимать формулировку задач на их языке.
— А другим сотрудникам и новым студентам не мешает отсутствие психологического бэкграунда?
— Здесь важно понимать, что мы именно работаем с данными. Мы не можем сами из воздуха ставить задачу – все они возникают в сотрудничестве с различными медицинскими организациями или научными проектами. Мы работаем с Научным центром неврологии, с Научным центром психического здоровья, с разными международными инициативами. Получаем от них задачи, уточняем их, проговариваем вместе, что именно интересно проверить на основе данных. Сами мы ни в коем случае не биологи и не врачи, наши компетенции совсем другие: мы занимаемся интересными и сложными задачами в области анализа данных и готовим алгоритмы для будущих медицинских применений. И это невероятно интересно!
Михаил Петров, ТАСС-Чердак
|








