>> Задачи для поступления
Ниже представлен актуальный список задач для собеседований (весна 2024).
Вам нужно выбрать одну задачу из данного списка и подготовить по ней доклад с презентацией.
Пожалуйста, заранее убедитесь, что Ваш доклад занимает не более 7 минут (регламент жесткий во избежание накладок в расписании). После доклада у Вас будет (15 − продолжительность доклада) минут на беседу с комиссией.
Собеседования будут проходить очно по адресу: Большой Каретный переулок, д. 19 стр. 1 (ст. м. Цветной бульвар и Трубная).
Чтобы быть в курсе всех новостей и организационной информации, присоединяйтесь к нашему Телеграм-каналу.
Задача 1. Алгоритм денойзинга BM3D

В статье разбирается алгоритм денойзинга, основанный на классических методах анализа изображений. Несмотря на то, что алгоритм был создан в 2007 году, из-за своей эффективности он до сих пор используется как референс при сравнении с новыми методами обесшумливания изображений.
Задача
Разобрать статью, подробно рассказать об алгоритме и реализовать его на языке по выбору*.
Вопросы
-
Что такое шум? Какой есть типы шума?
-
Из каких основных этапов состоит алгоритм? Расскажите о главных идеях этапов.
-
Как реализуется агрегация патчей, как оцениваются пиксели? Как взвешиваются патчи в первом и втором этапе?
-
Каким образом происходит совместная фильтрация? Расскажите о математическом аппарате оценки 3D-группы в первом и втором этапе.
-
Преобразование Уолша-Адамара. Как применяется, какие особенности присутствуют в алгоритме?
-
Способы оценки результата. Плюсы и минусы метрик.
Бонусные задания
-
Как применить алгоритм для цветных изображений? Расскажите об особенностях применения алгоритма, переходе из одного цветового пространство в другое.
-
Самостоятельно реализуйте алгоритм на языке по выбору. Предоставьте код и результаты работы алгоритма на своих изображениях.
По любым возникающим вопросам обращаться к Олегу Карасёву в тг @yasnohmuro.
Задача 2. Разбор обзорной статьи WaRP и реализация бейзлайнов.

В статье представлен обзор существующих датасетов и моделей в сфере автоматического распознавания ценных фракций отходов, реализованы SOTA решения в таких задачах компьютерного зрения, как классификация, детекция и weakly-supervised сегментация объектов.
Задача
Разобрать статью, рассказать о существующих датасетах и решениях по всем задачам. Реализовать представленные в статье архитектуры в задаче детекции, предоставить результаты обучения.
Вопросы и задачи:
-
Какие проблемы встречает исследователь в сфере распознавания ценных фракций отходов?
-
Набор данных в статье. Какие плюсы и минусы конкретных датасетов вы можете выделить.
-
Какие метрики оценки качества моделей используются в статье? Плюсы и минусы метрик, в каких случаях они используются и почему.
-
Что такое hierarchical detector? Расскажите про идею и реализацию в статье.
-
Реализация трёх топовых моделей детекции, презентация кода и результатов инференса.
-
* Реализация всех моделей детекции.
По любым возникающим вопросам обращаться к Олегу Карасёву в тг @yasnohmuro.
Задача 3. Почему классические алгоритмы лучше выполняют цветовые преобразования, чем нейронные сети?

Одной из важнейших задач компьютерного зрения является качественная цветопередача. Вместе с развитием технологий по регистрации изображений, их визуализации, развиваются и методы обработки цветовых изображений. Основная цель — повышение качества цветовой репродукции! В работе коллектив авторов, в числе которых Г. Финлейсон — видный великобританский профессор из этой области, исследует вопрос точной цветопередачи разными методами. Вам предстоит разобраться в этой аналитической работе и сделать доклад по ней.
Материалы для подготовки: лекция 1, лекция 2.
Вопросы:
-
Зачем решать задачу перехода из пространства камеры в пространство стандартного наблюдателя? Почему это различные пространства?
-
В чем основная сложность задачи перехода из одного цветового пространства в другое? Что такое метамеризм? Что такое условие Лютера?
-
В чем заключаются недостатки линейной и полиномиальной регрессии?
-
Как измеряется ошибка цветопередачи?
-
Почему нейросети всё ещё уступают в данной задаче классическим алгоритмам?
Вопросы по задаче: https://t.me/korch_sergey в тг.
Удачи!
Задача 4. Как канадцам Планк помог
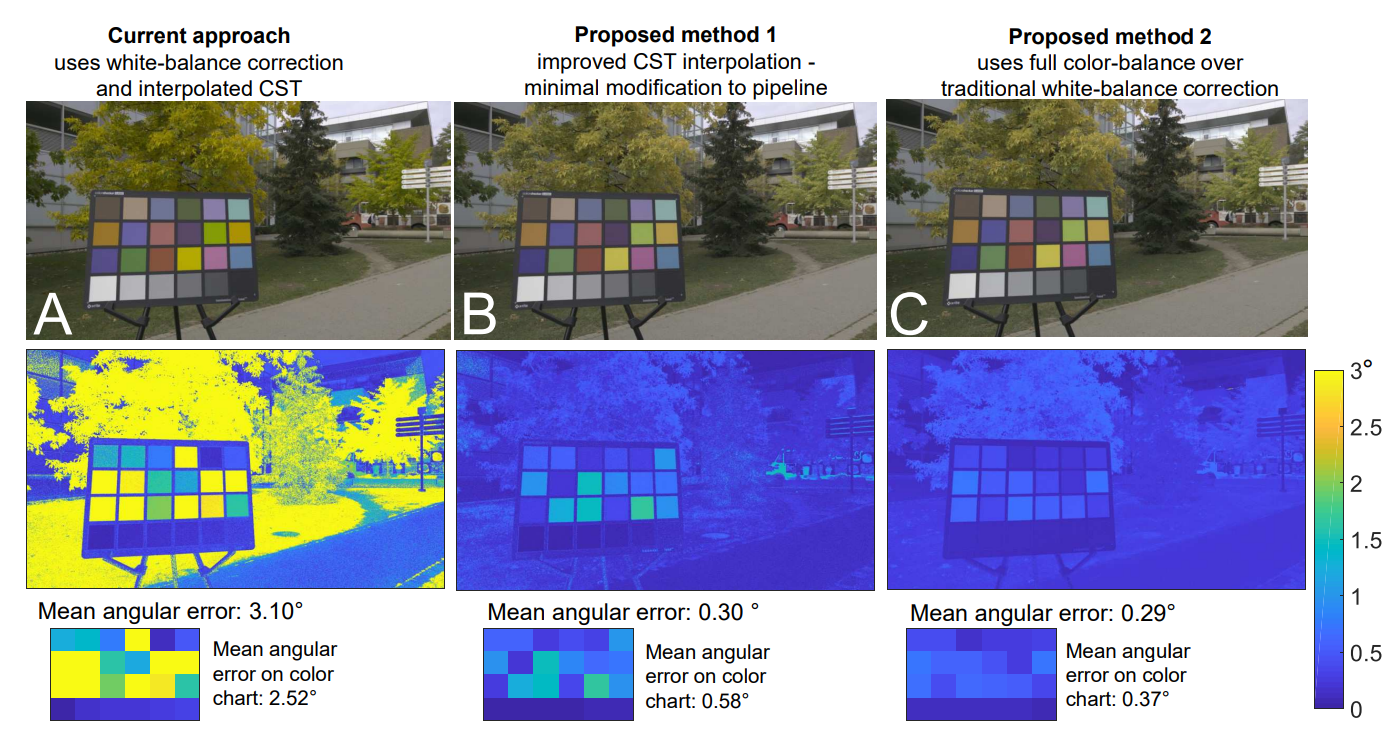
Предлагается разобраться в статье, посвященной переходу теме цветового менеджмента о новом алгоритме перехода в интерфейсное пространство цветов стандартного наблюдателя Karaimer, Hakki Can, and Michael S. Brown. - Improving color reproduction accuracy on cameras. CVPR. 2018.
Необходимо разобраться со следующими частями:
- В чем состоит задача перехода в пространство стандартного наблюдателя и почему она сложна?
- В чем заключается идея, предложенная авторами в этой работе?
- Как работает предложенный авторами алгоритм? Что такое цветовой треугольник? Где там живёт планковская кривая? Почему она важна?
- Какие сильные и слабые стороны у предложенного решения?
Так как время доклада существенно ограничено, не следует акцентировать внимание на базовых вещах. Тем не менее, подразумевается, что вы полностью понимаете то, о чем говорите. Собственная имплементация предложенного алгоритма или более простых (например линейных) алгоритмов повысит ваши шансы и поможет лучше разобраться в задаче.
Вопросы по задаче: ershov@iitp.ru с темой письма: “собеседование ИППИ”
Удачи!
Задача 5. Как телефоном выбрать краску для авто?

Исследователей в области цвета и цветовой вычислительной фотографии давно интересует вопрос: а насколько точно можно определить спектр окраски наблюдаемого объекта используя обычную камеру? Ведь если можно, то это позволит решить кучу задач удалённой медицины, точного определения цвета продуктов для интернет-рынка и так далее. Этой теме посвящено много научных работ, в том числе сотрудников Сектора 11.1 ИППИ РАН. Вам предлагается разобраться в одной из них. Необходимо разобраться со следующими частями:
- В чем состоит задача спектральной реконструкции?
- В чем заключается идея, предложенная авторами в этой работе?
- Как работает предложенный авторами алгоритм? Что такое метамеры и как это связано с линейной алгеброй?
- Какие сильные и слабые стороны у предложенного решения?
Так как время доклада существенно ограничено, не следует акцентировать внимание на базовых вещах. Тем не менее, подразумевается, что вы полностью понимаете то, о чем говорите. Собственная имплементация предложенного алгоритма или более простых (например линейных) алгоритмов повысит ваши шансы и поможет лучше разобраться в задаче.
Вопросы по задаче: @AgentKolobok (Телеграм).
Удачи!
Задача 6. Разбор статьи по CLIP IQA
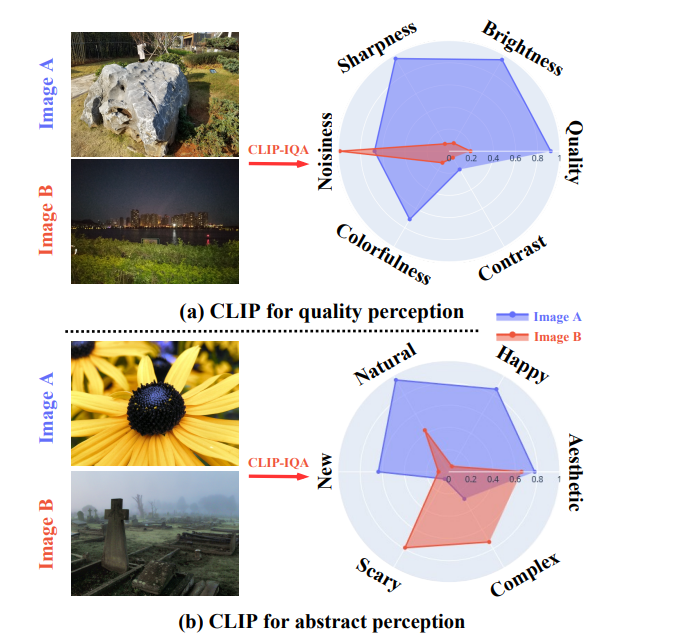
В статье исследуется проблему оценки качества изображений (IQA) с использованием модели глубокого обучения CLIP (Contrastive Language–Image Pretraining). Основная идея заключается в том, чтобы использовать эмбеддинги изображений и текста, полученные из модели CLIP, для предсказания качества изображений. Этот подход предлагает эффективный способ IQA без необходимости обучения модели на больших наборах данных оценок качества.
Задача
Разобрать статью (и статью про сам CLIP), подробно рассказать об идеях обеих статей и воспроизвести результаты работы, связанные с IQA (таблица 1 в статье)*.
Вопросы
-
что такое IQA? В чем отличие объективного IQA от субъективного?
-
В чем основная идея CLIP? (как его обучали?)
-
Каким образом формировался рейтинг для изображения (вопрос про cosine similarity + softmax)?
-
Что такое SROCC и PLCC?
-
Какое нововведение сделали авторы статьи для повышения метрик?
-
Зачем вообще изначально нужен был positional embedding в CLIP?
Бонусные задания
-
Посчитать SROCC/PLCC для KonIQ-10k, LIVE-itW или SPAQ. Нарисовать зависимость MOS и выдаваемых метрик, по МНК оценить коэффициенты прямой зависимости.
-
Рассказать про энкодеры у CLIP: небольшой экскурс в мир ViT и ResNet
По любым возникающим вопросам тыкаться в тг к Артёму Паншину @neverlios.
Задача 7. Планирование выполнения расчета в распределенной вычислительной системе.
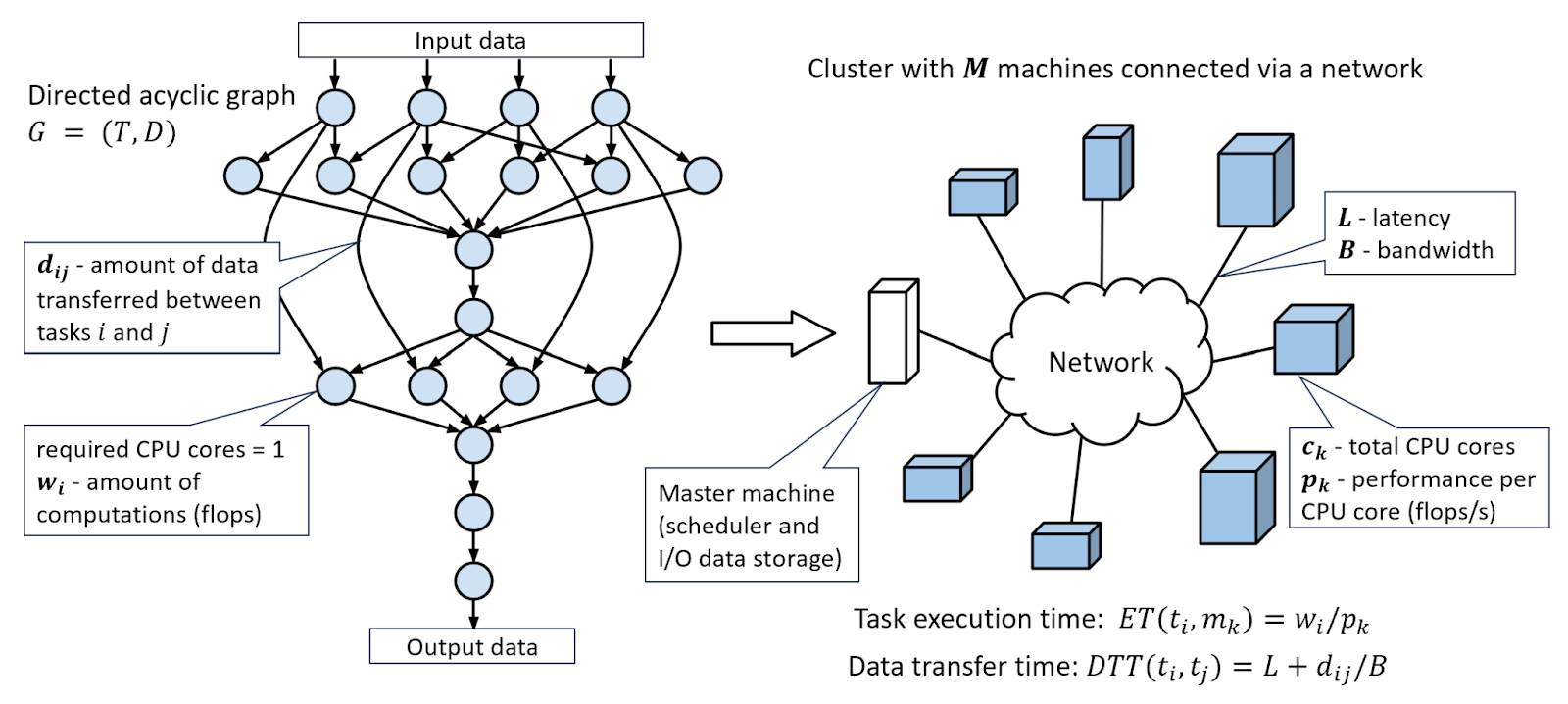
Имеется распределенная система, состоящая из M вычислительных узлов. Узел k имеет ck ядер с производительностью pk (число выполняемых операций в секунду). Характеристики разных узлов могут отличаться друг от друга. Узлы соединены сетью с пропускной способностью B (число передаваемых байтов в секунду).
В этой системе требуется выполнить некоторый расчет, состоящий из T отдельных вычислительных задач. Задачи могут зависеть от данных, вычисляемых другими задачами. Таким образом, расчет можно описать в виде направленного ациклического графа (DAG), вершинами которого являются задачи, а дуги описывают зависимости по данным между задачами. Для каждой задачи i известен требуемый объем вычислений - число операций wi, откуда можно вычислить время исполнения задачи на узле по его производительности. Для каждой зависимости (i,j) известно число байтов dij, передаваемых от задачи i к задаче j. Данная модель описывает многие реальные вычислительные приложения, такие как научные workflow, инженерные расчёты или пайплайны обработки данных.
Задача. Опишите, реализуйте и протестируйте алгоритм, строящий расписание выполнения задач в системе (на каком узле и когда будет запущена каждая задача) с целью минимизации времени выполнения всего расчета (время окончания последней задачи) при следующих ограничениях:
-
В каждый момент времени узел может выполнять одновременно не более ck задач (каждая задача потребляет одно ядро).
-
Задача может начать выполняться на узле только тогда, когда завершатся все родительские задачи и данные от них будут переданы на этот узел. Если задачи выполняются на разных узлах, то данные между ними передаются за время dij/B. В случае выполнения на одном узле передача происходит мгновенно.
Алгоритм может не гарантировать оптимальность построенного расписания, но должен стремиться как можно больше уменьшить время расчета. Можно придумать алгоритм самому или же, изучив литературу по теме DAG scheduling, взять алгоритм из одной из статей. Для тестирования алгоритма можно воспользоваться примерами систем и расчетов из этого репозитория и фреймворком DSLab DAG.
По любым возникающим вопросам обращаться к Олегу Сухорослову @osukhoroslov.
Задача 8. Разбор статьи по способам решения обратных задач с диффурами в рамках развития SvF-технологии
Представьте себя Иоганном Кеплером или Исааком Ньютоном, которые разглядывают астрономические схемы движения планет Солнечной системы и пытаются на основании этих (к тому же неточных !!!) данных вывести закономерности орбитальной динамики. Вспомните насколько “просто” выглядит закон всемирного тяготения Ньютона, который вместе со его же 2-ым законом движения (в дифференциальной форме) позволяет неплохо моделировать движение небесных тел.
В некотором смысле, эта “историческая аналогия” неплохо иллюстрирует типовую ситуацию: исследователь пытается вывести строгие математические закономерности поведения динамической системы на основании имеющихся у него неполных и неточных сведений о “положениях” этой системы в некоторые моменты времени. Если наш исследователь имеет основания полагать, что эти закономерности имеют вид дифференциального уравнения, то ему понадобится определить вид правой части такого уравнения. Именно эту проблему, иногда, называют обратной задачей, т.к. здесь не требуется рассчитать траекторию (решая “прямую” задачу Коши), а, наоборот, по набору точек на траектории определить сам диффур.
В предлагаемая вашему разбору статье намечаются способы решения таких обратных задач в рамках технологии сбалансированной идентификации математических моделей, которая, для краткости, названа SvF-технологией (Simplicity vs Fitting). Эта технология развивается сотрудниками нашего института уже несколько лет, доведена до программной реализации, https://github.com/distcomp/SvF и ее представлена на портале сервисов оптимизационного моделирования на платформе Everest. Можно отметить, что SvF-технология успешно применяется в различных исследованиях, где требуется построить структурную математическую модель изучаемого явления: в биологии, популяционной динамике, биологии растений, физике плазмы, метеорологии, экологии.
После опубликования предлагаемой к разбору статьи, изложенный там метод был доработан до случая обычных (а не только автономных) дифференциальных уравнений с одной или двумя переменными. При этом стало ясно, что предлагаемое тема решения обратных задач на основе конечномерной оптимизации подразумевает много возможностей для дипломных и, даже, кандидатских работ как по развитию численных методов “дискретизации”, так и по важным вопросам их программной реализации с использованием современных солверов для задач математического программирования, включая задачи глобальной оптимизации.
По всем возникающим вопросам по этой теме можно обращаться к Владимиру Волошинову https://t.me/VladVol или vladimir.voloshinov@gmail.com
Задача 9. Сравнение kmeans и EM алгоритма
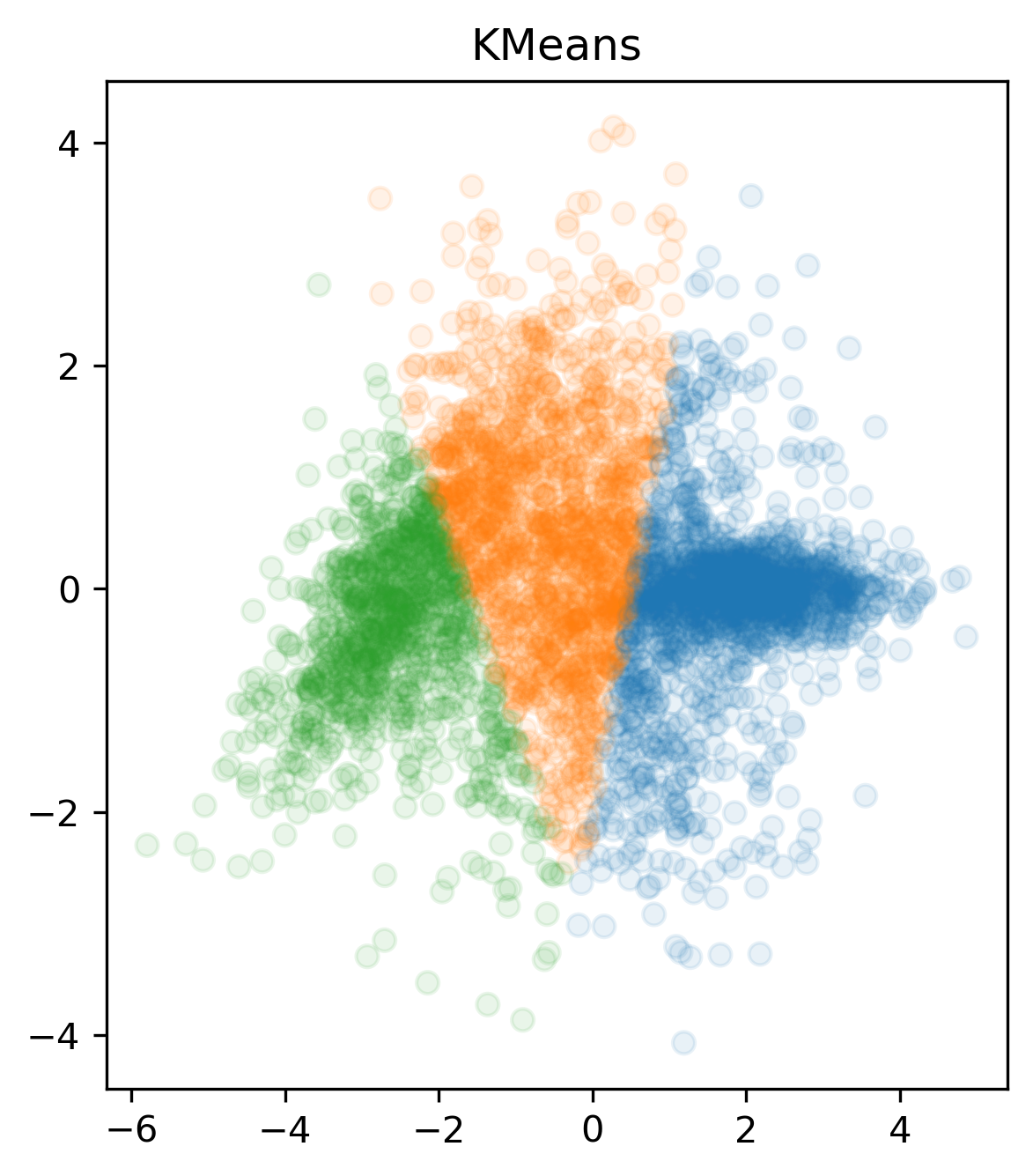 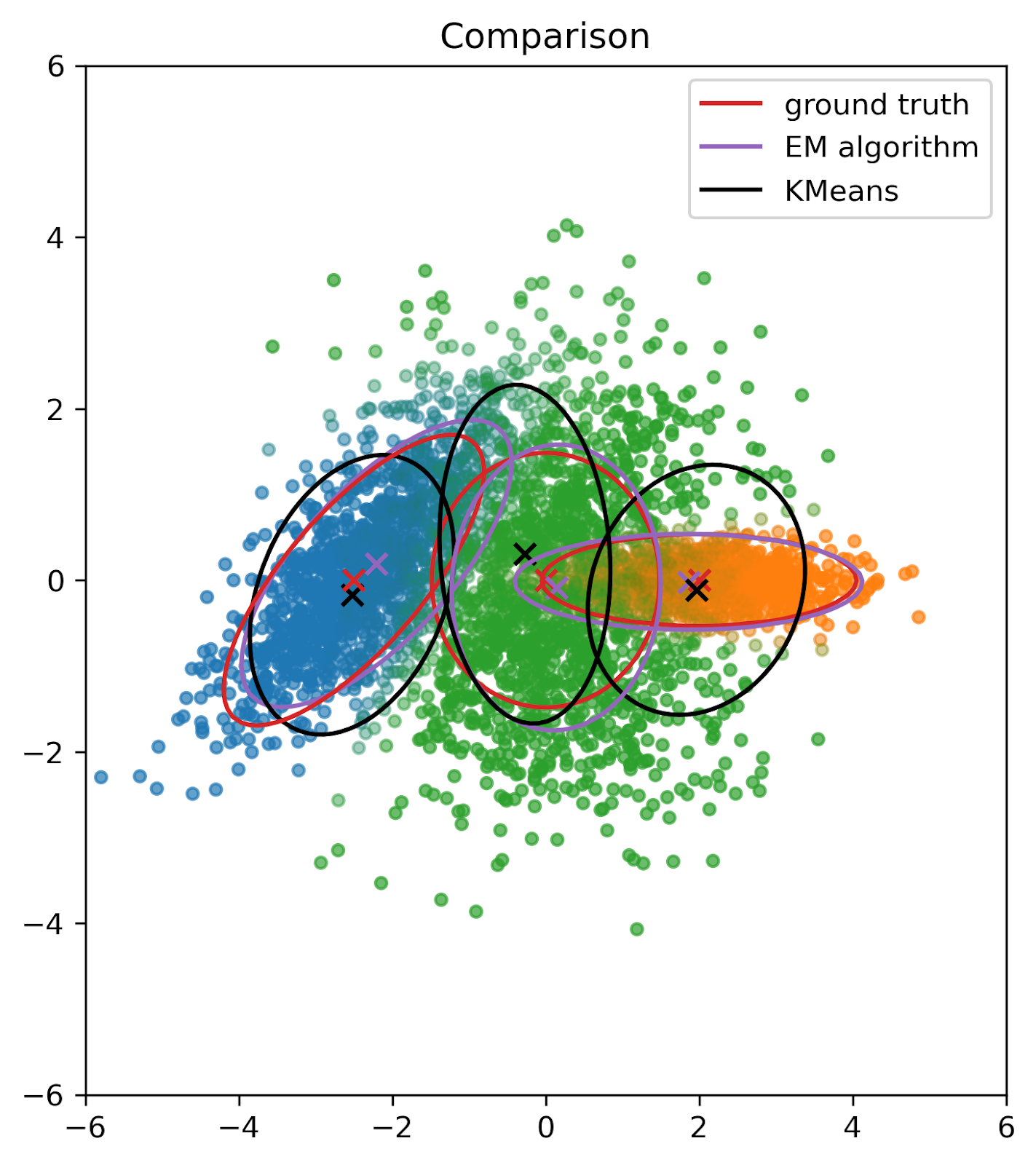
EM алгоритм и алгоритм KMeans являются двумя популярными методами кластеризации данных. Оба алгоритма используются для разделения набора данных на группы или кластеры на основе их сходства.
Задача: Вам нужно реализовать EM алгоритм и сравнить работу EM алгоритма и KMeans на заданном датасете. Используйте библиотечную реализацию KMeans из sklearn. Для инициализации EM алгоритма используйте KMeans.
-
Разобраться в EM алгоритме (знать в чём состоят шаги и понимать почему они работают) [можно начать с конспекта]
-
Написать код для разделения смеси нормальных распределений и применить его к датасету (2-мерный torch.Tensor)
-
Построить как алгоритмы разделяют датасет на кластеры и изолинии для каждого из получившихся распределений
-
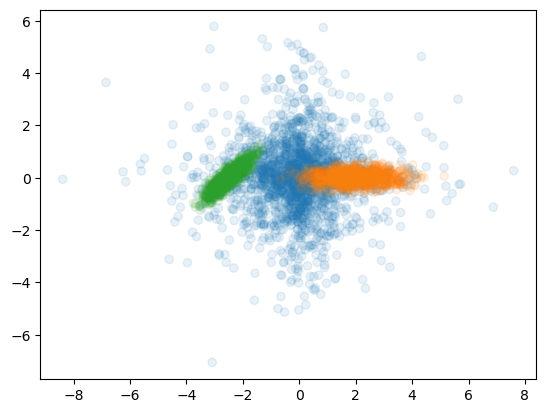
Модифицируйте свой код для разделения смеси 2х нормальных и одного лапласовского распределения. Запустите свой код на данном датасете. Должно получиться как-то так:
Вопросы:
-
Как работает EM алгоритм
-
Почему EM алгоритм работает ?
-
Какие недостатки у EM алгоритма ?
-
В чём сложность разделения разных классов распределений ?
По любым возникающим вопросам обращаться в тг к Всеволоду Плохотнюку @vsevolod-pl.
Задача 10. Влияние ядерных испытаний на землетрясения

В интернете несколько лет назад распространилась публикация, что во время ядерных испытаний (45-63 гг.) снизилось количество сильных землетрясений, в частности не было землетрясений с магнитудой больше 8.3.
Задача. Ваша задача — разобраться в этом вопросе и проверить, насколько справедлива такая гипотеза. Результат заранее мне не известен.
Землетрясения образуют график повторяемости, следующий из закона Гутенберга – Рихтера log10N= a - bM, где N – число землетрясений, a – число, пропорциональное активности и b – наклон графика повторяемости, а M – магнитуда. Очевидно, что если у нас стало меньше сильных землетрясений, то наклон b должен быть больше во время ядерных испытаний, чем после их запрещений. В этом и состоит первичная задача. На следующем этапе можно проверить, как изменяется b в разных регионах и что из этого можно извлечь (не только ведь ядерные испытания влияют на b). Хороший каталог землетрясений можно брать из ISC (https://doi.org/10.31905/D808B830) или NEIC (https://earthquake.usgs.gov/earthquakes/search/). Надо разобраться какие магнитуды бывают, в чем их отличие друг от друга (например, https://doi.org/10.1093/gji/ggu264, https://doi.org/10.1007/s10950-006-9012-4) и выбрать какую-либо одну. Оценивать параметр b можно по этой статье (http://hdl.handle.net/2122/1017) или по этой (https://doi.org/10.1007/s10950-016-9589-1). Дополнительная информация для изучения в этих статьях (https://doi.org/10.1016/j.tecto.2013.12.001, https://doi.org/10.1016/j.earscirev.2017.07.008)
По любым возникающим вопросам обращаться в тг к Александру Дерендяеву @wintsa
Задача 11. Обнаружение семантических сдвигов
Естественный язык постоянно меняется. В нем, в частности, не только появляются новые слова, но и меняются значения существующих. Эти изменения не обязательно связаны с изменением значения во времени. Например, они могут быть связаны с особенностями употребления слова в текстах различных областей знаний (не путать с явлением омонимии). Для обнаружения этого явления, называемого семантическим сдвигом, хорошо зарекомендовали себя неконтекстуализированные векторные представления слов.
Вам предлагается реализовать один из подходов к решению этой задачи и проверить его эффективность качественно на конкретных примерах.
-
Разобраться со статьей https://aclanthology.org/P16-1141/. Уметь формулировать постановку задачи, предлагаемый авторами подход к решению и алгоритмы получения векторных представлений слов.
-
Скачать корпус текстов OpenCorpora (https://www.opencorpora.org/?page=downloads)
-
Выбрать два типа текстов из набора: ЧасКор (новости), Википедия, Блоги, Худ. литература, Нон-фикшн (см. https://www.opencorpora.org/?page=genre_stats). Извлечь из корпуса все тексты выбранных типов и сгруппировать по типу.
-
Выбрать (и обосновать выбор) один из алгоритмов получения векторных представлений слов, упомянутых в статье, и реализовать его. Например, можно использовать библиотеку gensim (https://radimrehurek.com/gensim/), и тогда реализация любого из алгоритмов из статьи будет сводиться скорее к предобработке текстов корпуса.
-
Получить векторные представления слов для каждого из двух выбранных типов текстов.
-
Обнаружить семантические сдвиги, обусловленные различиями в типах текстов, как минимум для трех слов, используя подход, предложенный в статье. Проанализировать эти сдвиги на качественном уровне исходя из собственного понимания языка.
Доп. задания:
-
Найти слово, для которого семантический сдвиг нельзя объяснить различиями в типах текстов, а можно объяснить только в диахронии.
-
Найти слово, для которого семантический сдвиг нельзя объяснить различиями в типах текстов, а можно объяснить только явлением омонимии.
Контакт для связи: @derise (Андрей)
Задача 12. Кто мечтает быть пилотом…
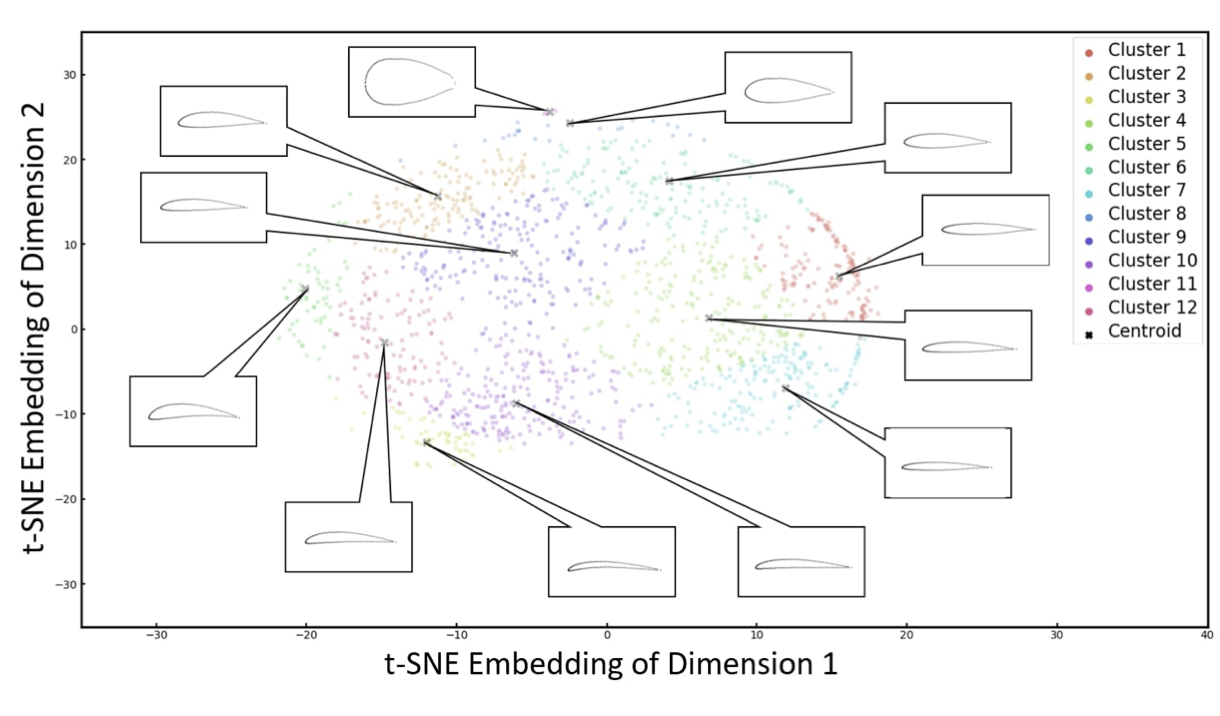
Написать VAEGAN, описанный в статье, без оптимизации формы (оптимизировать веса модели очевидно нужно 😀)
Аэродинамические профили (двумерный срез крыла) намного проще обучать, чем картинки, поскольку представление данных одномерное. Более того, это решает задачу параметризации аэродинамического профиля для последующего поиска оптимальной формы.
Вопросы:
-
Почему форма шумит, т. е. в целом пытается выдать форму профиля, но сами линии ломанные?
-
Почему вывод иногда коллапсирует в одну точку?
-
Поможет ли линейная свертка на выходе сгладить результат и чем это грозит?
-
Построить TSNE визуализацию и график лосса, чем отличается с математической точки зрения поиск наилучшей точки в GAN от обычных нейронок?
-
На TSNE построить траекторию изменения одного из эмбеддинговых параметров случайного профиля и вывести как меняется его форма.
-
Почему нужно понизить размерность пространства для того чтобы сэмплить из случайного распределения, причем тут генеративные сети.
-
Какой уже реализованный baseline подойдет для этой задачи?
Любые вопросы и активность по задаче категорически приветствуются: @leo_sabantsev.
Задача 13. Задача о поиске числа с особой структурой в битовом представлении

Вопросы по задаче: ershov@iitp.ru с темой письма: “собеседование ИППИ”
Удачи!
Задача 14. О позиционировании фотокамеры

Имеется фотокамера, все внутренние параметры которой известны. На фотографии, сделанной этой камерой, найдены и различены изображения трёх точек, положение которых в системе координат сцены известно. Какие выводы можно сделать о положении камеры относительно сцены в момент снимка?
Обращаться к @alatkon.
Задача 15. Проблема машинлёрнера
Некоторый сервис позволяет машинлёрнеру генерировать случайные нейросетевые модели. Истинное качество 𝑞 («посчитанное» на генеральной совокупности) этих моделей неизвестно и описывается нормальным распределением: 𝑞 ∼ 𝒩 (0, 𝜎12). Однако доступна оценка 𝑞approx качества модели, посчитанная на валидационной выборке. Известно, что 𝑞approx является зашумлённым истинным качеством 𝑞approx ∼ 𝒩 (𝑞, 𝜎22). Машинлёрнер независимо генерирует 𝑛 моделей и выбирает ту из них, на которой значение 𝑞approx максимально, причём оно оказывается равным 𝑞approx*. Вычислите математическое ожидание и плотность вероятности истинного качества 𝑞 для выбранной модели.
Обращаться к @alatkon.
Задача 16. О монетах

Требуется разработать систему определения суммарного номинала монет по фотографии.
Вход: Изображение (фотография) плоской поверхности, на которой в произвольном порядке расположены монеты. Все монеты из известного набора (напр., российские рубли и копейки), но могут также присутствовать посторонние объекты, не перекрывающие обзор.
Выход: Оценка суммарного номинала монет. При невозможности дать однозначный ответ указать возможный интервал либо варианты ответа.
Допущения: рассмотрите следующие случаи, предложите методы решения и повышения точности распознавания. Выберете, для какой их комбинации реализация вам по силам, и запрограммируйте решение:
- Все монеты расположены номиналом («решкой») вверх;
- На снимке присутствуют монеты всех возможных номиналов;
- Снимок сделан камерой с известными параметрами с известным положением относительно плоскости стола;
- Положение и параметры камеры неизвестны;
- Оптическая ось камеры перпендикулярна поверхности стола;
- Оптическая ось камеры наклонена на небольшой (до 20 градусов) неизвестный угол от вертикали;
- Стол нетекстурированный;
- Текстура стола не содержит окружностей;
- Монеты могут частично перекрываться;
- И т.п. — можете сформулировать свои допущения.
Обращаться к @bocharo.
Задача 17. Индекс структурированности

Предложите и реализуйте способ (способы — чем больше и разнообразней, тем лучше) оценки «структурированности» изображения. Т.е. индикации того, что на изображении не случайный шум, а на самом деле что-то изображено.
Вход: одноканальное изображение.
Выход: число, высокие значения соответствуют изображениям с очевидной структурой, низкие — случайному шуму без явной пространственной структуры. Ниже приведены примеры изображений в порядке возрастания требуемого числа (слева направо, сверху вниз).
Обращаться к @bocharo.
Задача 18. Унимодальная регрессия

Задача 19. Реализация алгоритма бинаризации

Одной из стандартных задач обработки изображений является задача бинаризации. Она заключается в определении для каждого пикселя изображения определённого класса (1 или 0). Классический пример — у нас на входе фотография изображения с текстом, а нам нужно определить какой пиксель относится к фону, а какой к тексту. В рамках этого трека вам предлагается прочитать 3 классические статьи: “A threshold selection method from gray-level histograms” за авторством Otsu и две её модификации: “Maximum likelihood thresholding based on population mixture models” от Kurita и “Minimum error thresholding” за авторством Kittler–Illingworth.
После чтения статей вам нужно ответить на ряд вопросов:
- Когда задача бинаризации в целом имеет смысл? Приведите примеры использования помимо в анализе исторических текстов.
- Какие методы использовались для решения задачи бинаризации?
- В чём их преимущества и недостатки?
- Какой из этих методов работает лучше для задачи бинаризации исторических документов и почему?
- Как можно расширить методы, представленные в статье на случай бинаризации многих классов?
- Оцените сложность этих методов.
- Какие метрики используются для оценки качества бинаризации? В чём их преимущества и недостатки?
Прочитайте дополнительно статью “A generalization of Otsu method for linear separation of two unbalanced classes in document image binarization”. Расскажите, в чём основной посыл статьи? Каким образом авторы предлагают расширить метод оцу на случай двумерного признакового пространства? Какие проблемы это помогает решать?
Оригинальные алгоритмы (Оцу, Курита, Китлер-Иллингворт) нужно реализовать и протестировать на открытом датасете снимков исторических текстов: https://vc.ee.duth.gr/dibco2019/. Посчитайте для них метрику Pseudo F-measure, проанализируйте ошибки, отрисуйте гистограммы яркости и выясните какой метод работает лучше.
Обращаться к https://t.me/korch_sergey в тг.
Задача 20. Регрессия на основе сглаживающих сплайнов



Ссылки
[1] Главы 5.1-5.5 и упражнение 5.7 из The Elements of Statistical Learning.
По вопросам писать Михаилу Гончарову (tg: @misha_goncharov
Задача 21. word2vec
Разобраться в статье [1] и имплементировать (см. [2]) на тексте «Война и Мир» Л.Н. Толстого.
Ссылки
[1] Mikolov, Tomas, et al. "Distributed Representations of Words and Phrases and their Compositionality."Advances in Neural Information Processing Systems, vol. 26, 2013 (link).
[2] Example of implementation.
По вопросам писать Михаилу Гончарову (tg: @misha_goncharov).
Задача 22. Прогнозирование засухи
Задача прогнозирования засухи состоит в том, чтобы спрогнозировать индекс засухи для конкретной территории на некоторое время вперед (например, на несколько месяцев) по заданной истории. В нашем случае мы будем использовать Индекс серьезности засухи Палмера (PDSI). Кроме того, используя некоторые пороговые значения, можно рассматривать прогнозирование засухи как задачу классификации.
Основное задание заключается в том, чтобы предсказать PDSI на 12 месяцев вперед по данным. Разбиение на обучающую и тестовую выборку делайте в пропорции 0,7:0,3. Используйте линейные модели (Linear, NLinear и DLinear) из статьи. Поскольку эти модели предназначены только для временных данных, вам следует расширить их для эффективного учета как пространственных, так и временных зависимостей (попробуйте свои собственные гипотезы). Качество предсказания оценивайте с помощью метрик R^2, MSE, MAE, RMSE.
Бонусные задания:
-
Вместо предсказания PDSI, попробуйте решить классификационные задачи:
- бинарная классификация: порог = -2, PDSI < -2 => засуха есть. Метрики: ROCAUC, PRAUC, F1.
- трёхклассовая классификация: пороги = [-2, 2]. Метрика: Accuracy.
-
Вместо линейных моделей попробуйте использовать для предсказания:
По вопросам писать Alexander.Marusov@skoltech.ru.
Задача 23. Адверсальные атаки
Адверсальные атаки — это специальные методы преобразования исходных данных для снижения качества прогнозов модели. Адверсальные атаки очень популярны в области компьютерного зрения, но они также могут быть применимы и к области временных рядов. Основная проблема использования адверсальных атак в области временных рядов заключается в том, что их легко обнаружить с помощью специальной модели классификатора (дискриминатора).
Базово ваша задача заключается в том, чтобы разобраться с двумя статьями про существующие методы адверсальных атак в области временных рядов: IFGSM и DeepFool.
Бонусное задание является практическим:
-
Обучите TimesNet, в качестве набора данных используйте датасет FordA для бинарной классификации. Вы можете использовать другой классификатор временных рядов и/или другой набор данных для классификации на свой выбор.
-
Атакуйте эту модель с помощью IFGSM и/или DeepFool.
-
Обучите дискриминатор для проверки наличия адверсальной атаки.
-
Оцените скрытность и эффективность атак с помощью следующих метрик:
- effectiveness = 1 - accuracy_{attacked model}
- concealability = 1 - accuracy_{discriminator model}
По вопросам обращаться к @Petr_Sokerin в telegram.
Задача 24. Обобщенная изопериметрическая задача на многограннике
А. П. Афанасьев, Дифференциальные уравнения, ноябрь 1993 г., том 29, № 11

Задача 25. Локальные методы федеративного обучения
- Решение задание можно, например, оформить в виде Jupyter Notebook.
- Файл с решением задания необходимо назвать: Группа Фамилия Имя. Пример: 007 Иванов Иван.
- Итоговое решение нужно отправлять на OptimizationHomework@yandex.ru. Тема письма: МФТИ тест.
- Каждая из 4х частей задания будет оцениваться от 0 до 4х баллов. Порог прохождения будет выставлен, исходя из общей картины всех полученных решений. Предположительно порог будет равен 8.
- С авторами хороших решений, предполагается беседа по заданию и не только, по итогам которой и принимается решение о рекомендации к поступлению на кафедру.
Желаем успехов!
В рамках данного задания Вам предстоит разобрать с результатами из статей:
[1] Communication-Efficient Learning of Deep Networks from Decentralized Data
[2] Tighter Theory for Local SGD on Identical and Heterogeneous Data
[3] SCAFFOLD: Stochastic Controlled Averaging for Federated Learning
Нужно будет прочитать 1 или 2 статьи: [1] или [2], или [1,3], или [2,3]. Статьи [1] и [2] рассказывают про один и тот же метод, но с разных точек зрения: [1] – более инженерная и без математики, [2] – более теоретическая. Прочитать сразу две новые статьи довольно сложно, поэтому уже хорошо, если получится прочитать статью [1] или [2].
Укажите в начале решения, какой из вариантов для чтения Вы выбрали.
Предполагается, что задание проверяет, насколько Вы самостоятельно можете проводить исследование и читать статьи. Но если у Вас возникает ряд вопросов, без ответов на которые не сможете выполнить задание, то их можно задать в телеграмме @abeznosikov или на почту beznosikov.an@phystech.edu.
Часть 1. Постановка задачи
– Опишите, как данная постановка с функциями 𝑓𝑖 связана с задачей машинного обучения: "У нас есть обучающая выборка из матрицы объектов 𝑋 и меток 𝑦, есть модель 𝑔 с весами 𝑤. Обучите модель."
– В чем заключаются особенности постановки, рассматриваемой авторами?
- Какую информацию о функциях 𝑓𝑖 , мы можем вычислять/хотим использовать? Попробуйте описать, почему именно такого рода информацию мы хотим использовать.
- Попробуйте проанализировать предположения на целевые функции. Насколько они кажутся правдоподобными?
Часть 2. Разбор и сравнение результатов научных статей
- Дочитайте статью/статьи до конца.
- Какие сильные и слабые стороны предложенных подходов выделяют авторы? Из-за чего возникают слабые стороны? Можно ли их устранить?
- Если Вы работает со статьями [2], [2,3], объясните теоретические результаты сходимости, полученные в статьях. Расскажите, как теоретические результаты зависит от тех или иных свойств постановки задачи или настроек метода.
- Изучите экспериментальные результаты, представленные авторами. Какие особенности работы методов проявляются в экспериментах?
- Если Вы работаете со статье [3], постарайтесь объяснить, чем результаты метода SCAFFOLD лучше, чем для FedAvg/Local SGD.
Часть 3. План численного эксперимента
- Выберите задачу машинного обучения, которую хотите решать. Это может быть хоть обучение нейронной сети, но мы рекомендуем остановиться на обучении логистической регрессии, как в [2].
- Подберите данные для задачи обучения. Например, можете использовать датасеты из LibSVM.
- Так как в работах рассматриваются распределенные задачи. Для постановки экспериментов Вам придется воспроизвести распределенные вычисления на своем персональном компьютере (или Colab и т.п.). Делать реальные распределенные вычисления необязательно (более того, мы не рекомендуем – уйдет слишком много времени), достаточно просто описать, как Вы симулируете распределенность задачи: как разделите данные (учтите, что авторы в статьях уделяют этому много внимания), как будете производить вычисления на различных устройствах.
- Опишите все предыдущие пункты в виде плана. Расскажите, какие постановки будете пробовать в первую очередь, как измерять результаты и сравнивать методы между собой (обратите внимание на построение графиков – изучите, какие графики строят авторы).
Часть 4. Численный эксперимент
- Реализуйте все необходимые вещи в коде. Кратко опишите, за что отвечают те или иные большие части кода (где метод, где реализация подсчета функции, где построение графиков и т.п.)
- Поставьте численные эксперимент согласно плану, которые описали в предыдущем пункте.
- Сделайте выводы из экспериментов. Подтверждают ли Ваши выводы теорию из статей? Подтверждаются ли глобальные выводы авторов?
Задача 26. Некоторые свойства задач оптимизации типа QUBO
По вопросам обращаться к @VladVol в Телеграм.
| 









