>> Задачи для поступления >> Задачи осень 2023
Задача 1. Размытие

Дискретная свёртка — операция, широко используемая в обработке сигналов, а благодаря возможности обобщить её на двумерные массивы — и в обработке изображений. Сворачивая изображение с различными ядрами, можно достичь различных эффектов, таких как выделение границ, размытие, резкость и т. д. Гауссовское ядро является самым популярным для размытия, но не единственным возможным.
В этой задаче вам даны две картинки: исходная и свёрнутая с неизвестным ядром размытия (при помощи функции filter2D из питоновской библиотеки opencv-python). Вам нужно вычислить это самое ядро размытия.
Для этого вам потребуются:
-
быстрое преобразование Фурье (рекомендуется использовать готовую реализацию в NumPy);
-
теорема о свёртке;
-
знание о том, как избежать проблем, вызванных шумом;
-
кое-какая эвристика, необходимость которой вы осознаете, приступив к задаче.
Поскольку точно восстановить ядро размытия невозможно, требуется лишь приближенная оценка. Для самопроверки можно использовать следующий критерий: у получившегося ядра разница между соседями по вертикали не должна превышать 0,05. На языке NumPy: np.abs(np.diff(reconstructed_kernel, axis=0)).max() < 0.05.
Вопросы
-
Как делать свёртку при помощи быстрого преобразования Фурье?
-
Чем такая свёртка будет отличаться от свёртки при помощи упомянутой в условии функции filter2D?
-
Какая из этих свёрток подразумевается в теореме о свёртке?
Помощь с непонятками / консультацию / психологическую помощь можно запрашивать по адресу cromtus собака яндекс ру.
Задача 2. Пёс? Или всё же кот...

Одной из актуальных задач машинного обучения является оценка неопределённости. Неопределённость — характеристика отдельного элемента выборки, которую можно рассматривать как уверенность модели в правильности своего предсказания на этом элементе: на объектах с высокой неопределённостью хорошо обученная модель вероятно ошибётся, а на объектах с низкой — ответит верно.
Как правило, выделяют два основных фактора, вносящих вклад в неопределённость:
-
объект имеет двойственную природу, лежит на пересечении классов (котопёс в задаче классификации кошки/собаки);
-
модель тестируется на данных, которые существенно отличаются от обучающей выборки (обучающая выборка — кошки/собаки, тестовая — жирафы).
Материалы:
Для общего понимания полезен вот этот курс (в частности первые 2-3 лекции), эта обзорная статья (полностью разбирать не нужно), а также вот этот сайт.
Базовое задание заключается в том, чтобы разобраться в теории и ответить на следующие
Вопросы
-
Зачем оценивать неопределённость?
-
Что из себя представляют и чем отличаются неопределённость алеаторная и эпистемическая? (Спойлер: интуиция дана в условии задачи).
-
Какие существуют способы оценки алеаторной и эпистемической неопределённости? Рассказать про 3-4 (суммарно) понравившихся — много математики не требуется, достаточно идейного понимания (на чём основано и почему должно работать).
4. Как оценить оценку неопределённости? 🙂 Другими словами, после того как мы реализовали какой-то метод оценки неопределённости, как понять, хорошо ли он работает? Действительно ли то, что он возвращает, измеряет неопределённость? К числу основных подходов относится построение accuracy-rejection curve (когда требуется бинарная оценка неопределенности) и метрики калибровки: reliability diagrams, ECE (когда неопределенность соответствует вероятности, что модель допустила ошибку).
Существенным бонусом будет
пощупать неопределённость руками. Чтобы облегчить вам жизнь, ниже предлагается пример конкретной задачи, которую вы можете решить, но если вам интересно вместо/помимо этой задачи решить какую-то другую, в которой используется оценка неопределённости, это чудесно и тоже будет плюсом в карму :) Не стесняйтесь экспериментировать (творчество приветствуется) и помните, что отрицательный результат — тоже результат!
Бонусная задача. Попробуйте использовать оценку неопределённости для решения задачи out-of-distribution детекции. Идея в том, что у вас есть основной набор данных, на котором обучается модель, а также набор данных из немного другого распределения (похожий на первый, но все же имеющий существенные отличия). Тестовая выборка включает объекты из обоих наборов данных. Для каждого объекта вы хотите понимать, к какому набору данных он относится. Для этого для каждого объекта оценивается эпистемическая неопределенность — если она высокая, то объект out-of-distribution.
План действий:
-
Взять в качестве основного датасета MNIST, а в качестве out-of-distribution датасета — Fashion-MNIST, обучить или взять готовую модель для классификации MNIST-а.
-
Выбрать и реализовать один или несколько методов оценки неопределённости (например, MCDropout — в качестве модели выбирается нейросеть с dropout-ами, на тестовой выборке обученная модель прогоняется несколько раз с включенными dropout-ами (за счет заложенной в dropout-е рандомизации получается ансамбль). В качестве оценки неопределенности можно взять стандартное отклонение ответов нейросетей из полученного ансамбля).
-
В тестовую выборку основного датасета добавить объекты из out-of-distribution датасета и протестировать ваш способ оценки неопределенности: объекты с высокой неопределенностью в идеале должны быть теми и только теми объектами, которые взяты из out-of-distribution датасета, объекты с низкой неопределённостью — наоборот.
-
Оценить и сравнить качество работы разных методов оценки неопределённости путём построения accuracy-rejection curve.
Любые вопросы и активность по задаче категорически приветствуются! Писать @zay_rina в телеграм.
Задача 3. Почему классические алгоритмы лучше выполняют цветовые преобразования, чем нейронные сети?

Одной из важнейших задач компьютерного зрения является качественная цветопередача. Вместе с развитием технологий по регистрации изображений, их визуализации, развиваются и методы обработки цветовых изображений. Основная цель — повышение качества цветовой репродукции! В работе коллектив авторов, в числе которых Г. Финлейсон — видный великобританский профессор из этой области, исследует вопрос точной цветопередачи разными методами. Вам предстоит разобраться в этой аналитической работе и сделать доклад по ней.
Вопросы:
-
Зачем решать задачу перехода из пространства камеры в пространство стандартного наблюдателя? Почему это различные пространства?
-
В чем основная сложность задачи перехода из одного цветового пространства в другое? Что такое метамеризм? Что такое условие Лютера?
-
В чем заключаются недостатки линейной и полиномиальной регрессии?
-
Как измеряется ошибка цветопередачи?
-
Почему нейросети всё ещё уступают в данной задаче классическим алгоритмам?
Вопросы по задаче: https://t.me/korch_sergey в тг.
Удачи!
Задача 4. Как канадцам Планк помог
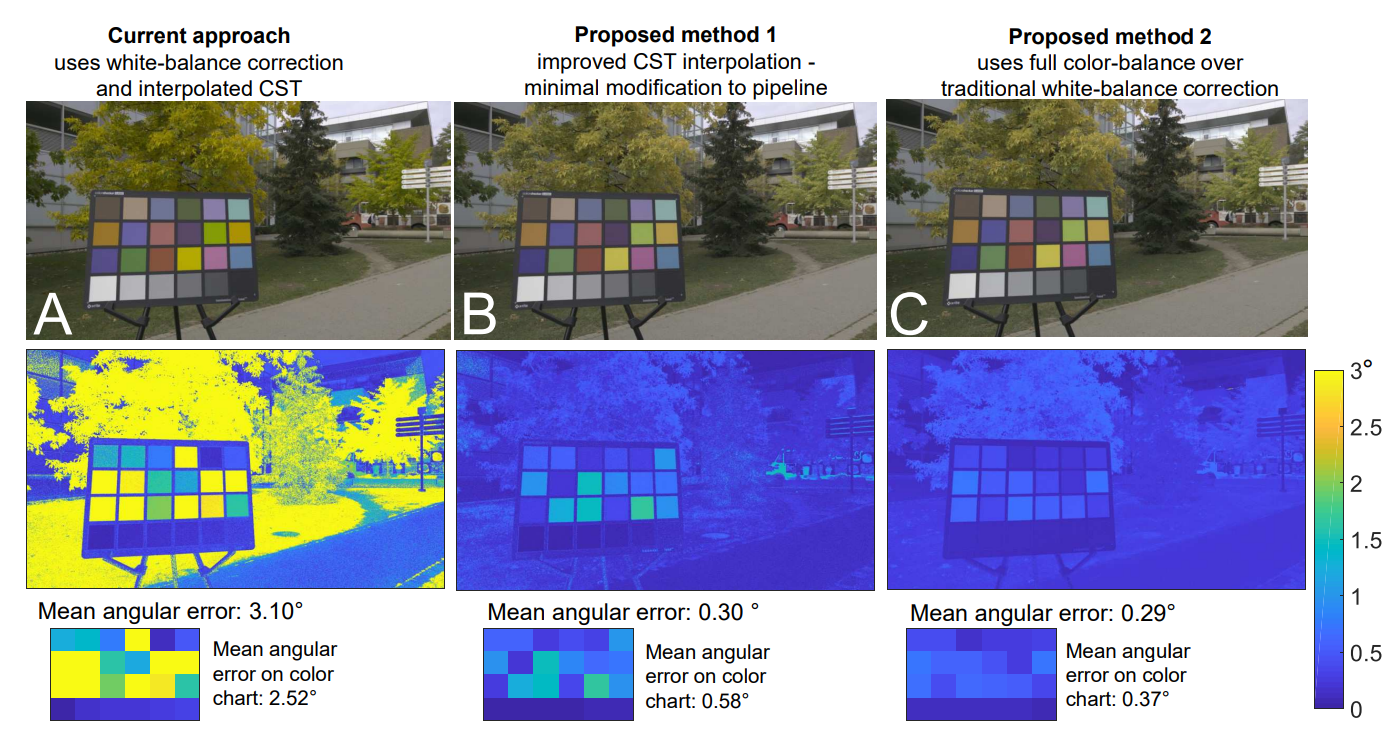
Предлагается разобраться в статье, посвященной переходу теме цветового менеджмента о новом алгоритме перехода в интерфейсное пространство цветов стандартного наблюдателя Karaimer, Hakki Can, and Michael S. Brown. - Improving color reproduction accuracy on cameras. CVPR. 2018.
Необходимо разобраться со следующими частями:
- В чем состоит задача перехода в пространство стандартного наблюдателя и почему она сложна?
- В чем заключается идея, предложенная авторами в этой работе?
- Как работает предложенный авторами алгоритм? Что такое цветовой треугольник? Где там живёт планковская кривая? Почему она важна?
- Какие сильные и слабые стороны у предложенного решения?
Так как время доклада существенно ограничено, не следует акцентировать внимание на базовых вещах. Тем не менее, подразумевается, что вы полностью понимаете то, о чем говорите. Собственная имплементация предложенного алгоритма или более простых (например линейных) алгоритмов повысит ваши шансы и поможет лучше разобраться в задаче.
Вопросы по задаче: ershov@iitp.ru с темой письма: “собеседование ИППИ”
Удачи!
Задача 5. Как телефоном выбрать краску для авто?

Исследователей в области цвета и цветовой вычислительной фотографии давно интересует вопрос: а насколько точно можно определить спектр окраски наблюдаемого объекта используя обычную камеру? Ведь если можно, то это позволит решить кучу задач удалённой медицины, точного определения цвета продуктов для интернет-рынка и так далее. Этой теме посвящено много научных работ, в том числе сотрудников Сектора 11.1 ИППИ РАН. Вам предлагается разобраться в одной из них. Необходимо разобраться со следующими частями:
- В чем состоит задача спектральной реконструкции?
- В чем заключается идея, предложенная авторами в этой работе?
- Как работает предложенный авторами алгоритм? Что такое метамеры и как это связано с линейной алгеброй?
- Какие сильные и слабые стороны у предложенного решения?
Так как время доклада существенно ограничено, не следует акцентировать внимание на базовых вещах. Тем не менее, подразумевается, что вы полностью понимаете то, о чем говорите. Собственная имплементация предложенного алгоритма или более простых (например линейных) алгоритмов повысит ваши шансы и поможет лучше разобраться в задаче.
Вопросы по задаче: cromtus собака яндекс ру.
Удачи!
Задача 6. Кто мечтает быть пилотом…
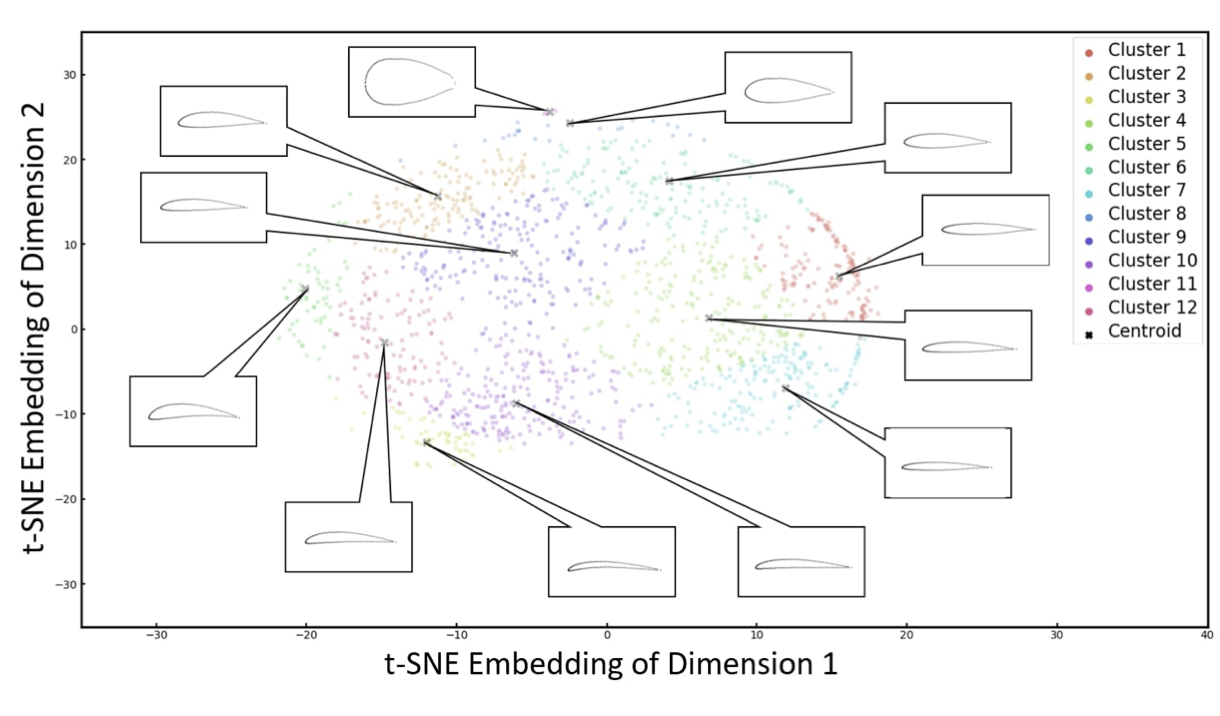
Написать VAEGAN, описанный в статье, без оптимизации формы (оптимизировать веса модели очевидно нужно 😀)
Аэродинамические профили (двумерный срез крыла) намного проще обучать, чем картинки, поскольку представление данных одномерное. Более того, это решает задачу параметризации аэродинамического профиля для последующего поиска оптимальной формы.
Вопросы:
-
Почему форма шумит, т. е. в целом пытается выдать форму профиля, но сами линии ломанные?
-
Почему вывод иногда коллапсирует в одну точку?
-
Поможет ли линейная свертка на выходе сгладить результат и чем это грозит?
-
Построить TSNE визуализацию и график лосса, чем отличается с математической точки зрения поиск наилучшей точки в GAN от обычных нейронок?
-
На TSNE построить траекторию изменения одного из эмбеддинговых параметров случайного профиля и вывести как меняется его форма.
-
Почему нужно понизить размерность пространства для того чтобы сэмплить из случайного распределения, причем тут генеративные сети.
-
Какой уже реализованный baseline подойдет для этой задачи?
Любые вопросы и активность по задаче категорически приветствуются: @leo_sabantsev.
Задача 7. Задача о поиске числа с особой структурой в битовом представлении

Вопросы по задаче: ershov@iitp.ru с темой письма: “собеседование ИППИ”
Удачи!
Задача 8. О позиционировании фотокамеры

Имеется фотокамера, все внутренние параметры которой известны. На фотографии, сделанной этой камерой, найдены и различены изображения трёх точек, положение которых в системе координат сцены известно. Какие выводы можно сделать о положении камеры относительно сцены в момент снимка?
Обращаться к @alatkon.
Задача 9. Проблема машинлёрнера
Некоторый сервис позволяет машинлёрнеру генерировать случайные нейросетевые модели. Истинное качество 𝑞 («посчитанное» на генеральной совокупности) этих моделей неизвестно и описывается нормальным распределением: 𝑞 ∼ 𝒩 (0, 𝜎12). Однако доступна оценка 𝑞approx качества модели, посчитанная на валидационной выборке. Известно, что 𝑞approx является зашумлённым истинным качеством 𝑞approx ∼ 𝒩 (𝑞, 𝜎22). Машинлёрнер независимо генерирует 𝑛 моделей и выбирает ту из них, на которой значение 𝑞approx максимально, причём оно оказывается равным 𝑞approx*. Вычислите математическое ожидание и плотность вероятности истинного качества 𝑞 для выбранной модели.
Обращаться к @alatkon.
Задача 10. О монетах

Требуется разработать систему определения суммарного номинала монет по фотографии.
Вход: Изображение (фотография) плоской поверхности, на которой в произвольном порядке расположены монеты. Все монеты из известного набора (напр., российские рубли и копейки), но могут также присутствовать посторонние объекты, не перекрывающие обзор.
Выход: Оценка суммарного номинала монет. При невозможности дать однозначный ответ указать возможный интервал либо варианты ответа.
Допущения: рассмотрите следующие случаи, предложите методы решения и повышения точности распознавания. Выберете, для какой их комбинации реализация вам по силам, и запрограммируйте решение:
- Все монеты расположены номиналом («решкой») вверх;
- На снимке присутствуют монеты всех возможных номиналов;
- Снимок сделан камерой с известными параметрами с известным положением относительно плоскости стола;
- Положение и параметры камеры неизвестны;
- Оптическая ось камеры перпендикулярна поверхности стола;
- Оптическая ось камеры наклонена на небольшой (до 20 градусов) неизвестный угол от вертикали;
- Стол нетекстурированный;
- Текстура стола не содержит окружностей;
- Монеты могут частично перекрываться;
- И т.п. — можете сформулировать свои допущения.
Обращаться к @bocharo.
Задача 11. Индекс структурированности

Предложите и реализуйте способ (способы — чем больше и разнообразней, тем лучше) оценки «структурированности» изображения. Т.е. индикации того, что на изображении не случайный шум, а на самом деле что-то изображено.
Вход: одноканальное изображение.
Выход: число, высокие значения соответствуют изображениям с очевидной структурой, низкие — случайному шуму без явной пространственной структуры. Ниже приведены примеры изображений в порядке возрастания требуемого числа (слева направо, сверху вниз).
Обращаться к @bocharo.
Задача 12. Унимодальная регрессия

Задача 13. Бинаризация

Одной из стандартных задач обработки изображений является задача бинаризации. Она заключается в определении для каждого пикселя изображения определённого класса (1 или 0). Классический пример — у нас на входе фотография изображения с текстом, а нам нужно определить какой пиксель относится к фону, а какой к тексту. В рамках этого трека вам предлагается прочитать 3 классические статьи: “A threshold selection method from gray-level histograms” за авторством Otsu и две её модификации: “Maximum likelihood thresholding based on population mixture models” от Kurita и “Minimum error thresholding” за авторством Kittler–Illingworth.
После чтения статей вам нужно ответить на ряд вопросов:
-
Какие методы использовались для решения задачи бинаризации?
-
В чём их преимущества и недостатки?
-
Какой из этих методов работает лучше для задачи бинаризации исторических документов и почему?
-
Как можно расширить методы, представленные в статье на случай бинаризации многих классов?
-
Оцените сложность этих методов? Какой математический трюк позволил Оцу резко сократить сложность метода?
-
Какие метрики используются для оценки качества бинаризации? В чём их преимущества и недостатки?
-
Прочитайте дополнительно статью “A generalization of Otsu method for linear separation of two unbalanced classes in document image binarization”. Расскажите, в чём основной посыл статьи? Каким образом авторы предлагают расширить метод оцу на случай двумерного признакового пространства?
-
** Придумайте свой алгоритм бинаризации, который мог бы помочь решить проблемы, возникающие в исторических документах (тени, печати, проникновение чернил сквозь страницу.
Оригинальные алгоритмы (Оцу, Курита, Китлер-Иллингворт) нужно реализовать и протестировать на открытом датасете снимков исторических текстов: https://vc.ee.duth.gr/dibco2019/
Обращаться к https://t.me/korch_sergey в тг.
Задача 14. Регрессия на основе сглаживающих сплайнов



Ссылки
[1] Главы 5.1-5.5 и упражнение 5.7 из The Elements of Statistical Learning.
По вопросам писать Михаилу Гончарову (tg: @misha_goncharov
Задача 15. word2vec
Разобраться в статье [1] и имплементировать (см. [2]) на тексте «Война и Мир» Л.Н. Толстого.
Ссылки
[1] Mikolov, Tomas, et al. "Distributed Representations of Words and Phrases and their Compositionality."Advances in Neural Information Processing Systems, vol. 26, 2013 (link).
[2] Example of implementation.
По вопросам писать Михаилу Гончарову (tg: @misha_goncharov).
Задача 16. Прогнозирование засухи
Задача прогнозирования засухи состоит в том, чтобы спрогнозировать индекс засухи для конкретной территории на некоторое время вперед (например, на несколько месяцев) по заданной истории. В нашем случае мы будем использовать Индекс серьезности засухи Палмера (PDSI). Кроме того, используя некоторые пороговые значения, можно рассматривать прогнозирование засухи как задачу классификации.
Основное задание заключается в том, чтобы предсказать PDSI на 12 месяцев вперед по данным. Разбиение на обучающую и тестовую выборку делайте в пропорции 0,7:0,3. Используйте линейные модели (Linear, NLinear и DLinear) из статьи. Поскольку эти модели предназначены только для временных данных, вам следует расширить их для эффективного учета как пространственных, так и временных зависимостей (попробуйте свои собственные гипотезы). Качество предсказания оценивайте с помощью метрик R^2, MSE, MAE, RMSE.
Бонусные задания:
-
Вместо предсказания PDSI, попробуйте решить классификационные задачи:
- бинарная классификация: порог = -2, PDSI < -2 => засуха есть. Метрики: ROCAUC, PRAUC, F1.
- трёхклассовая классификация: пороги = [-2, 2]. Метрика: Accuracy.
-
Вместо линейных моделей попробуйте использовать для предсказания:
По вопросам писать Alexander.Marusov@skoltech.ru.
Задача 17. Адверсальные атаки
Адверсальные атаки — это специальные методы преобразования исходных данных для снижения качества прогнозов модели. Адверсальные атаки очень популярны в области компьютерного зрения, но они также могут быть применимы и к области временных рядов. Основная проблема использования адверсальных атак в области временных рядов заключается в том, что их легко обнаружить с помощью специальной модели классификатора (дискриминатора).
Базово ваша задача заключается в том, чтобы разобраться с двумя статьями про существующие методы адверсальных атак в области временных рядов: IFGSM и DeepFool.
Бонусное задание является практическим:
-
Обучите TimesNet, в качестве набора данных используйте датасет FordA для бинарной классификации. Вы можете использовать другой классификатор временных рядов и/или другой набор данных для классификации на свой выбор.
-
Атакуйте эту модель с помощью IFGSM и/или DeepFool.
-
Обучите дискриминатор для проверки наличия адверсальной атаки.
-
Оцените скрытность и эффективность атак с помощью следующих метрик:
- effectiveness = 1 - accuracy_{attacked model}
- concealability = 1 - accuracy_{discriminator model}
По вопросам обращаться к @Petr_Sokerin в telegram.
| 







{kind=link}
